这是整理上万个素材,一个压缩文件匹配一张图片。命名相似(不完全相同),以TextMatchRate筛选,结果发现这个相似度是按含有的字符数量来计算,要命的是不按顺序!结果就成了看来完全不同的两文件名相似度很高!
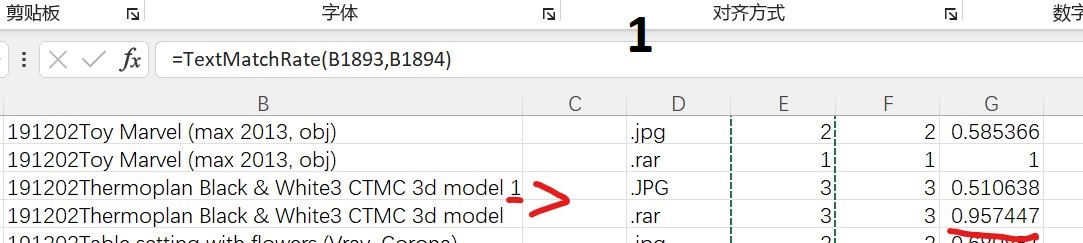
图1:39字符,一个多个“1”,为什么只有95%相似度?按字符比例来算也不止这么多?
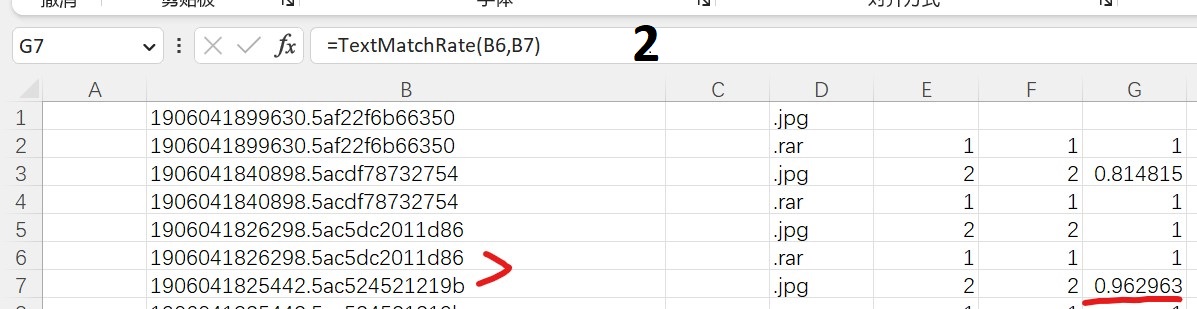
图2:明显不同字符很多为什么却达到96%相似度?这两文件一眼就看出不匹配
图3:前面同图1,前面安全相同,后面多个模型字符,前面相同35字符,后面多7个字符,相似度却只有80%?
这个算法肯定是全文匹配不是按顺序匹配的
回复:2楼
我是真得不理解这个匹配规则设定了,它的应用范围在哪儿我都想不出了。下面实验了123456789与987654321,匹配度100%还可以理解成不按顺序,有的字符都有。但改成下图这样还是100%匹配?就真不理解了。是都是数字原因?

 等级:初学者
等级:初学者

 等级:传说级人物
等级:传说级人物